
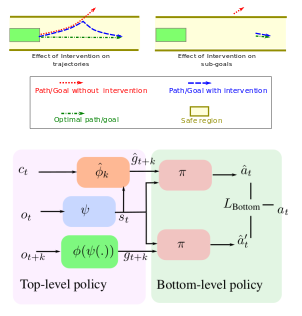
 We propose a hierarchical framework for Learning from Intervention to account
for expert’s reaction delay.
Learning from Demonstrations (LfD) via Behavior Cloning (BC) works well on multiple complex tasks. However, a limitation of the typical LfD approach is that it requires expert demonstrations for all scenarios, including those in which the algorithm is already well-trained. The recently proposed Learning from Interventions (LfI) overcomes this limitation by using an expert overseer. The expert overseer only intervenes when it suspects that an unsafe action is about to be taken. Although LfI significantly improves over LfD, the state-of-the-art LfI fails to account for delay caused by the expert’s reaction time and only learns short-term behavior. We address these limitations by 1) interpolating the expert’s interventions back in time, and 2) by splitting the policy into two hierarchical levels, one that generates sub-goals for the future and another that generates actions to reach those desired sub-goals. This sub-goal prediction forces the algorithm to learn long-term behavior while also being robust to the expert’s reaction time. Our experiments show that LfI using sub-goals in a hierarchical policy framework trains faster and achieves better asymptotic performance than typical LfD.
Paper
Bibtex
We propose a hierarchical framework for Learning from Intervention to account
for expert’s reaction delay.
Learning from Demonstrations (LfD) via Behavior Cloning (BC) works well on multiple complex tasks. However, a limitation of the typical LfD approach is that it requires expert demonstrations for all scenarios, including those in which the algorithm is already well-trained. The recently proposed Learning from Interventions (LfI) overcomes this limitation by using an expert overseer. The expert overseer only intervenes when it suspects that an unsafe action is about to be taken. Although LfI significantly improves over LfD, the state-of-the-art LfI fails to account for delay caused by the expert’s reaction time and only learns short-term behavior. We address these limitations by 1) interpolating the expert’s interventions back in time, and 2) by splitting the policy into two hierarchical levels, one that generates sub-goals for the future and another that generates actions to reach those desired sub-goals. This sub-goal prediction forces the algorithm to learn long-term behavior while also being robust to the expert’s reaction time. Our experiments show that LfI using sub-goals in a hierarchical policy framework trains faster and achieves better asymptotic performance than typical LfD.
Paper
Bibtex
Hierarchical policies for Learning from Intervention
Jing Bi, Vikas Dhiman, Tianyou Xiao, Chenliang Xu.
Learning from interventions using hierarchical policies for safe learning with delayed expert.