
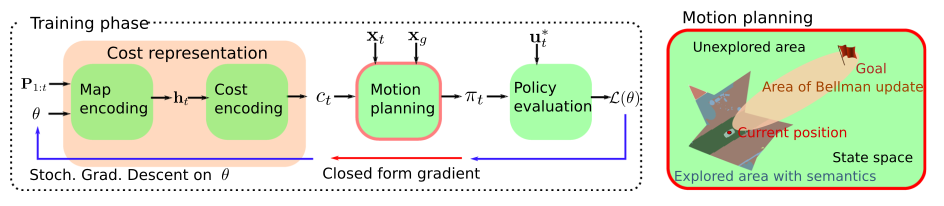
 This paper focuses on inverse reinforcement learning for autonomous navigation using distance and semantic category observations …
This paper focuses on inverse reinforcement learning for autonomous navigation using distance and semantic category observations …
papers
-
papers
-
Inverse reinforcement learning for autonomous navigation via differentiable semantic mapping and planning
-
Safe control synthesis with uncertain dynamics and constraints
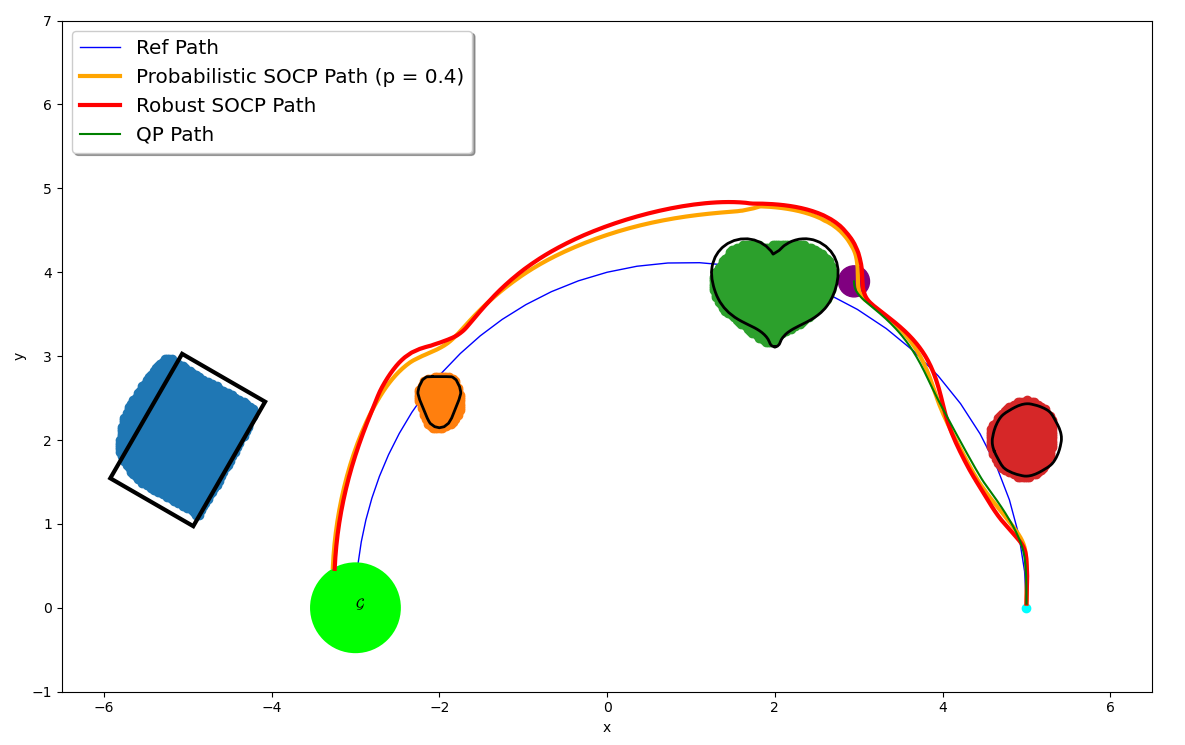 This paper considers safe control synthesis for dynamical systems in the presence of uncertainty in the dynamics model and the safety constraints that the system must satisfy. Our approach captures probabilistic and worst-case model errors and their effect on control Lyapunov function (CLF) and control barrier function (CBF) constraints in the control-synthesis optimization problem. We show that both the probabilistic and robust formulations lead to second-order cone programs (SOCPs), enabling safe and stable control synthesis that can be performed efficiently online. We evaluate our approach in PyBullet simulations of an autonomous robot navigating in unknown environments and compare the performance with a baseline CLF-CBF quadratic programming approach.
This paper considers safe control synthesis for dynamical systems in the presence of uncertainty in the dynamics model and the safety constraints that the system must satisfy. Our approach captures probabilistic and worst-case model errors and their effect on control Lyapunov function (CLF) and control barrier function (CBF) constraints in the control-synthesis optimization problem. We show that both the probabilistic and robust formulations lead to second-order cone programs (SOCPs), enabling safe and stable control synthesis that can be performed efficiently online. We evaluate our approach in PyBullet simulations of an autonomous robot navigating in unknown environments and compare the performance with a baseline CLF-CBF quadratic programming approach. -
Journal papers submitted and I am in job market.
Submitted journal papers Control Barriers in Bayesian Learning of System Dynamics, Object residual constrained Visual-Inertial Odometry and Learning Navigation Costs from Demonstrations with Semantic Observations.
Also, I am in the job market. Here is my CV. -
Probabilistic Safety Constraints
 How do you ensure safety when the robot behavior is only known with uncertainty?
We propose Probabilistic Safety Constraints for High Relative Degree System
Dynamics. We show how to learn a system with a Bayesian Learning method that
keeps track of uncertainty while ensuring safety upto an acceptable risk factor,
for example, 99.999%.
We use the framework of Control Barrier Functions and extend it to higher-order
relative degree systems while propagating uncertainty in model dynamics to the
safety constraints.
How do you ensure safety when the robot behavior is only known with uncertainty?
We propose Probabilistic Safety Constraints for High Relative Degree System
Dynamics. We show how to learn a system with a Bayesian Learning method that
keeps track of uncertainty while ensuring safety upto an acceptable risk factor,
for example, 99.999%.
We use the framework of Control Barrier Functions and extend it to higher-order
relative degree systems while propagating uncertainty in model dynamics to the
safety constraints. -
Hierarchical policies for Learning from Intervention
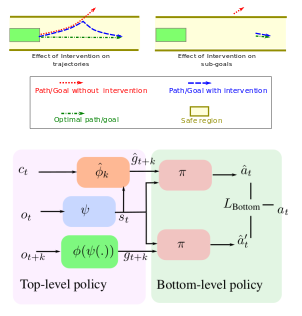 We propose a hierarchical framework for Learning from Intervention to account
for expert’s reaction delay.
Learning from Demonstrations (LfD) via Behavior Cloning (BC) works well on multiple complex tasks. However, a limitation of the typical LfD approach is that it requires expert demonstrations for all scenarios, including those in which the algorithm is already well-trained. The recently proposed Learning from Interventions (LfI) overcomes this limitation by using an expert overseer. The expert overseer only intervenes when it suspects that an unsafe action is about to be taken. Although LfI significantly improves over LfD, the state-of-the-art LfI fails to account for delay caused by the expert’s reaction time and only learns short-term behavior. We address these limitations by 1) interpolating the expert’s interventions back in time, and 2) by splitting the policy into two hierarchical levels, one that generates sub-goals for the future and another that generates actions to reach those desired sub-goals. This sub-goal prediction forces the algorithm to learn long-term behavior while also being robust to the expert’s reaction time. Our experiments show that LfI using sub-goals in a hierarchical policy framework trains faster and achieves better asymptotic performance than typical LfD.
Paper
Bibtex
We propose a hierarchical framework for Learning from Intervention to account
for expert’s reaction delay.
Learning from Demonstrations (LfD) via Behavior Cloning (BC) works well on multiple complex tasks. However, a limitation of the typical LfD approach is that it requires expert demonstrations for all scenarios, including those in which the algorithm is already well-trained. The recently proposed Learning from Interventions (LfI) overcomes this limitation by using an expert overseer. The expert overseer only intervenes when it suspects that an unsafe action is about to be taken. Although LfI significantly improves over LfD, the state-of-the-art LfI fails to account for delay caused by the expert’s reaction time and only learns short-term behavior. We address these limitations by 1) interpolating the expert’s interventions back in time, and 2) by splitting the policy into two hierarchical levels, one that generates sub-goals for the future and another that generates actions to reach those desired sub-goals. This sub-goal prediction forces the algorithm to learn long-term behavior while also being robust to the expert’s reaction time. Our experiments show that LfI using sub-goals in a hierarchical policy framework trains faster and achieves better asymptotic performance than typical LfD.
Paper
Bibtex