
Announcing the ICRA 2025 Workshop on “Robot safety under uncertainty from “intangible” specifications.” on May 19th, 2025. Calling for 2-4 page papers and a junior researcher talk on the topic of robot safety. https://iscicra25.github.io/. Deadline: April 15th, 2025
-
Updates
-
ICRA 2025 Workshop on Robot safety under uncertainty from “intangible” specifications
-
A conversation at Cenovus
Cenovus conversation
Prompted by: Christopher Ewanik
Material by: Vikas Dhiman, University of Maine, Orono -
KAN Kolmogorov-Arnold Networks A review
On Apr 30, 2024, Komogorov-Arnold Networks paper appears on ArXiV and by May 7th, I have heard about this paper from multiple students, from whom I do not hear about new papers. It must be special, I thought. I decided to take a look. I make 4 major critques of the paper
- MLPs have learnable activation functions as well
- The content of the paper does not justify the name, Kolmogorov-Arnold networks (KANs).
- KANs are MLPs with spline-basis as the activation function.
- KANs do not beat the curse of dimensionality. Link to the review, PDF.
-
Inverse reinforcement learning for autonomous navigation via differentiable semantic mapping and planning
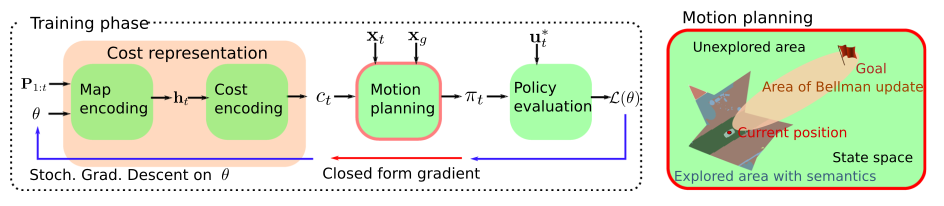 This paper focuses on inverse reinforcement learning for autonomous navigation using distance and semantic category observations …
This paper focuses on inverse reinforcement learning for autonomous navigation using distance and semantic category observations … -
Talk on safe autonomous navigation
 I gave an invited talk on “Autonomous navigation and safety” to FET MRIIRS faculty and students.
I gave an invited talk on “Autonomous navigation and safety” to FET MRIIRS faculty and students. -
Safe control synthesis with uncertain dynamics and constraints
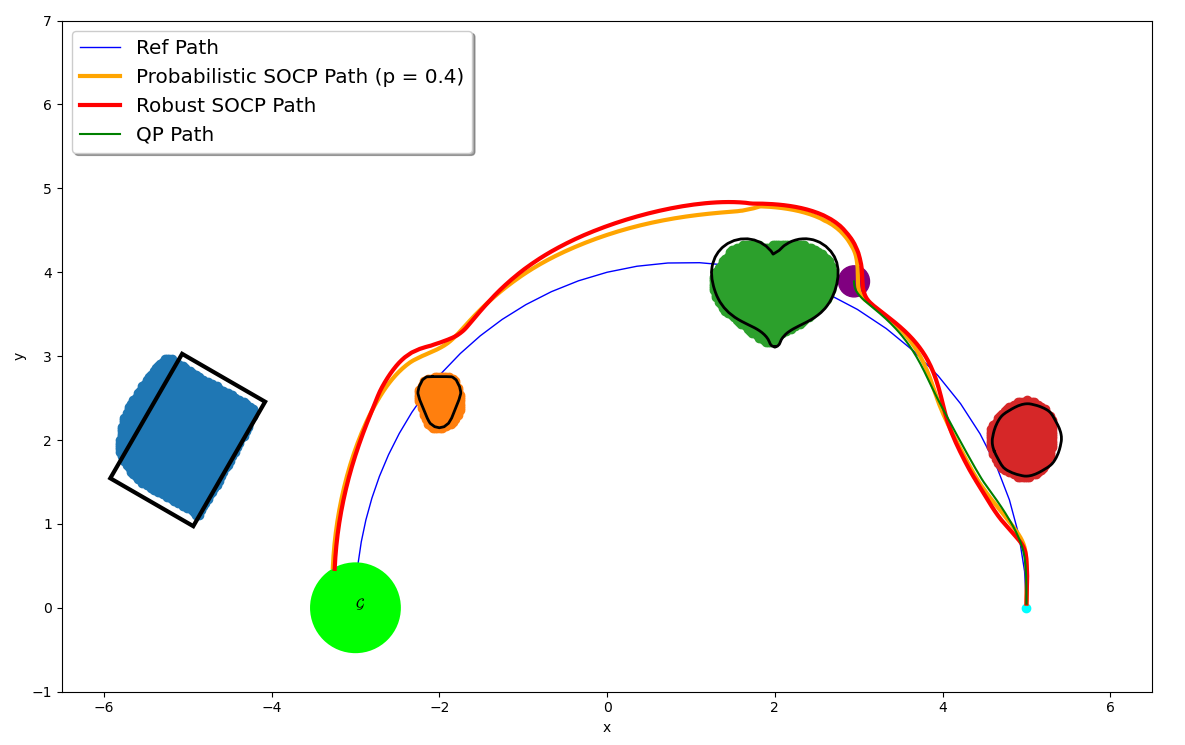 This paper considers safe control synthesis for dynamical systems in the presence of uncertainty in the dynamics model and the safety constraints that the system must satisfy. Our approach captures probabilistic and worst-case model errors and their effect on control Lyapunov function (CLF) and control barrier function (CBF) constraints in the control-synthesis optimization problem. We show that both the probabilistic and robust formulations lead to second-order cone programs (SOCPs), enabling safe and stable control synthesis that can be performed efficiently online. We evaluate our approach in PyBullet simulations of an autonomous robot navigating in unknown environments and compare the performance with a baseline CLF-CBF quadratic programming approach.
This paper considers safe control synthesis for dynamical systems in the presence of uncertainty in the dynamics model and the safety constraints that the system must satisfy. Our approach captures probabilistic and worst-case model errors and their effect on control Lyapunov function (CLF) and control barrier function (CBF) constraints in the control-synthesis optimization problem. We show that both the probabilistic and robust formulations lead to second-order cone programs (SOCPs), enabling safe and stable control synthesis that can be performed efficiently online. We evaluate our approach in PyBullet simulations of an autonomous robot navigating in unknown environments and compare the performance with a baseline CLF-CBF quadratic programming approach. -
Open PhD positions
I am hiring PhD students for Spring 2022. Please apply with your CV and a piece of sample code or project report that you are proud of. For details please refer to the attached flier.
-
ECE275 Sequential Logic Systems
The course syllabus is posted and the course website is up.
-
Recordings for ICRA'21 workshop on Safe Robot Control
The recordings for the ICRA’21 workshop on Safe Robot Control are available on youtube.
-
Joining University of Maine in August
I will be joining University of Maine as an Assistant Professor starting August.
-
ICRA'21 workshop on Safe Robot Control
Our ICRA’21 workshop on Safe Robot Control has been accepted and will be organized virtually. Please submit your contributions before April 17th, 2021.
-
Journal papers submitted and I am in job market.
Submitted journal papers Control Barriers in Bayesian Learning of System Dynamics, Object residual constrained Visual-Inertial Odometry and Learning Navigation Costs from Demonstrations with Semantic Observations.
Also, I am in the job market. Here is my CV. -
Probabilistic Safety Constraints
 How do you ensure safety when the robot behavior is only known with uncertainty?
We propose Probabilistic Safety Constraints for High Relative Degree System
Dynamics. We show how to learn a system with a Bayesian Learning method that
keeps track of uncertainty while ensuring safety upto an acceptable risk factor,
for example, 99.999%.
We use the framework of Control Barrier Functions and extend it to higher-order
relative degree systems while propagating uncertainty in model dynamics to the
safety constraints.
How do you ensure safety when the robot behavior is only known with uncertainty?
We propose Probabilistic Safety Constraints for High Relative Degree System
Dynamics. We show how to learn a system with a Bayesian Learning method that
keeps track of uncertainty while ensuring safety upto an acceptable risk factor,
for example, 99.999%.
We use the framework of Control Barrier Functions and extend it to higher-order
relative degree systems while propagating uncertainty in model dynamics to the
safety constraints. -
Hierarchical policies for Learning from Intervention
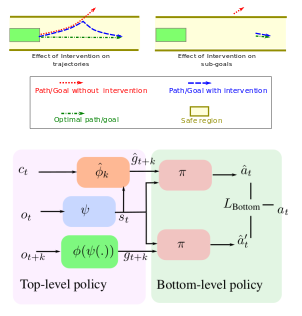 We propose a hierarchical framework for Learning from Intervention to account
for expert’s reaction delay.
Learning from Demonstrations (LfD) via Behavior Cloning (BC) works well on multiple complex tasks. However, a limitation of the typical LfD approach is that it requires expert demonstrations for all scenarios, including those in which the algorithm is already well-trained. The recently proposed Learning from Interventions (LfI) overcomes this limitation by using an expert overseer. The expert overseer only intervenes when it suspects that an unsafe action is about to be taken. Although LfI significantly improves over LfD, the state-of-the-art LfI fails to account for delay caused by the expert’s reaction time and only learns short-term behavior. We address these limitations by 1) interpolating the expert’s interventions back in time, and 2) by splitting the policy into two hierarchical levels, one that generates sub-goals for the future and another that generates actions to reach those desired sub-goals. This sub-goal prediction forces the algorithm to learn long-term behavior while also being robust to the expert’s reaction time. Our experiments show that LfI using sub-goals in a hierarchical policy framework trains faster and achieves better asymptotic performance than typical LfD.
Paper
Bibtex
We propose a hierarchical framework for Learning from Intervention to account
for expert’s reaction delay.
Learning from Demonstrations (LfD) via Behavior Cloning (BC) works well on multiple complex tasks. However, a limitation of the typical LfD approach is that it requires expert demonstrations for all scenarios, including those in which the algorithm is already well-trained. The recently proposed Learning from Interventions (LfI) overcomes this limitation by using an expert overseer. The expert overseer only intervenes when it suspects that an unsafe action is about to be taken. Although LfI significantly improves over LfD, the state-of-the-art LfI fails to account for delay caused by the expert’s reaction time and only learns short-term behavior. We address these limitations by 1) interpolating the expert’s interventions back in time, and 2) by splitting the policy into two hierarchical levels, one that generates sub-goals for the future and another that generates actions to reach those desired sub-goals. This sub-goal prediction forces the algorithm to learn long-term behavior while also being robust to the expert’s reaction time. Our experiments show that LfI using sub-goals in a hierarchical policy framework trains faster and achieves better asymptotic performance than typical LfD.
Paper
Bibtex -
Lecture on Particle, Kalman Filters and SLAM
A guest lecture on SLAM in Intro to Robotics on Oct 22, 2019. Colab Notebooks and slides
-
Named-tree programming style
Named-tree programming is a natural Pythonic functional programming paradigm. It encourages thinking of functions and classes as sub-trees in a bigger tree.
-
Defended my thesis on Localization, Mapping and Navigation
Defended my thesis on Dec 3, 2018. Thesis
-
A Critical Investigation of Deep Reinforcement Learning for Navigation
Paper, CodeWe find the Deep Reinforcement Learning for Navigation does not navigate on new maps.
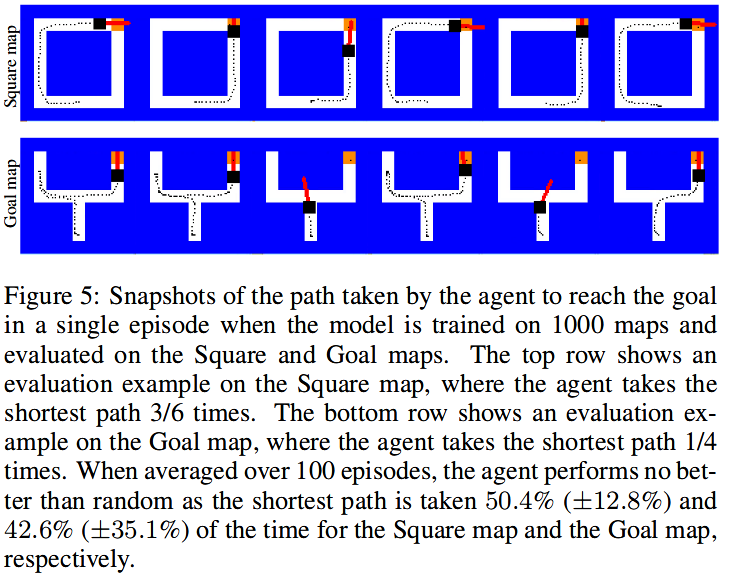 The navigation problem is classically approached in two steps: an exploration step, where map-information about the environment is gathered; and an exploitation step, where this information is used to navigate efficiently. Deep reinforcement learning (DRL) algorithms, alternatively, approach the problem of navigation in an end-to-end fashion. Inspired by the classical approach, we ask whether DRL algorithms are able to inherently explore, gather and exploit map-information over the course of navigation. We build upon Mirowski et al. [2017] work and introduce a systematic suite of experiments that vary three parameters: the agent's starting location, the agent's target location, and the maze structure. We choose evaluation metrics that explicitly measure the algorithm's ability to gather and exploit map-information. Our experiments show that when trained and tested on the same maps, the algorithm successfully gathers and exploits map-information. However, when trained and tested on different sets of maps, the algorithm fails to transfer the ability to gather and exploit map-information to unseen maps. Furthermore, we find that when the goal location is randomized and the map is kept static, the algorithm is able to gather and exploit map-information but the exploitation is far from optimal. We open-source our experimental suite in the hopes that it serves as a framework for the comparison of future algorithms and leads to the discovery of robust alternatives to classical navigation methods.
The navigation problem is classically approached in two steps: an exploration step, where map-information about the environment is gathered; and an exploitation step, where this information is used to navigate efficiently. Deep reinforcement learning (DRL) algorithms, alternatively, approach the problem of navigation in an end-to-end fashion. Inspired by the classical approach, we ask whether DRL algorithms are able to inherently explore, gather and exploit map-information over the course of navigation. We build upon Mirowski et al. [2017] work and introduce a systematic suite of experiments that vary three parameters: the agent's starting location, the agent's target location, and the maze structure. We choose evaluation metrics that explicitly measure the algorithm's ability to gather and exploit map-information. Our experiments show that when trained and tested on the same maps, the algorithm successfully gathers and exploits map-information. However, when trained and tested on different sets of maps, the algorithm fails to transfer the ability to gather and exploit map-information to unseen maps. Furthermore, we find that when the goal location is randomized and the map is kept static, the algorithm is able to gather and exploit map-information but the exploitation is far from optimal. We open-source our experimental suite in the hopes that it serves as a framework for the comparison of future algorithms and leads to the discovery of robust alternatives to classical navigation methods.
-
Lecture on Probabilistic Graphical Models
-
A Continuous Occlusion Model for Road Scene Understanding
Paper, Supplementary, BibtexWe propose to model cars as transparent ellipsoids rather cuboids to handle occlusion probabilistically.
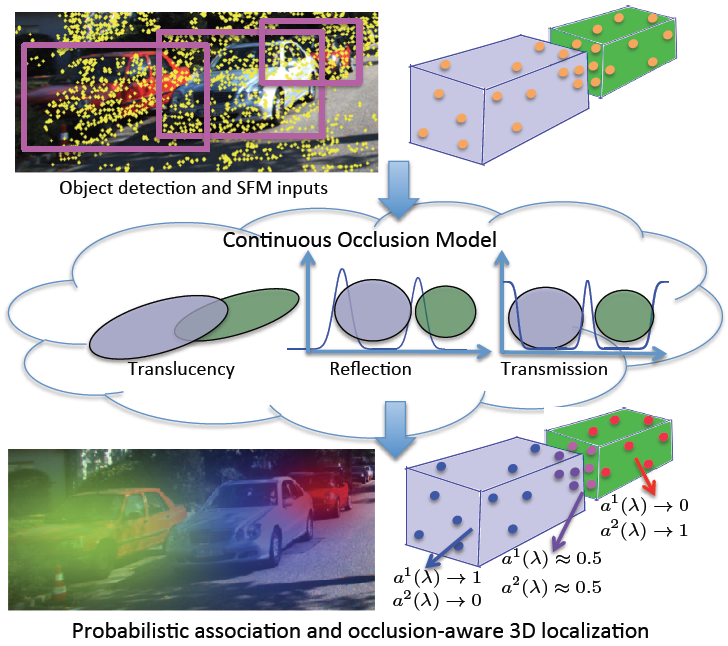 We present a physically interpretable, continuous three-dimensional (3D) model for handling occlusions with applications to road scene understanding. We probabilistically assign each point in space to an object with a theoretical modeling of the reflection and transmission probabilities for the corresponding camera ray. Our modeling is unified in handling occlusions across a variety of scenarios, such as associating structure from motion (SFM) point tracks with potentially occluding objects or modeling object detection scores in applications such as 3D localization. For point track association, our model uniformly handles static and dynamic objects, which is an advantage over motion segmentation approaches traditionally used in multibody SFM. Detailed experiments on the KITTI raw dataset show the superiority of the proposed method over both state-of-the-art motion segmentation and a baseline that heuristically uses detection bounding boxes for resolving occlusions. We also demonstrate how our continuous occlusion model may be applied to the task of 3D localization in road scenes.
We present a physically interpretable, continuous three-dimensional (3D) model for handling occlusions with applications to road scene understanding. We probabilistically assign each point in space to an object with a theoretical modeling of the reflection and transmission probabilities for the corresponding camera ray. Our modeling is unified in handling occlusions across a variety of scenarios, such as associating structure from motion (SFM) point tracks with potentially occluding objects or modeling object detection scores in applications such as 3D localization. For point track association, our model uniformly handles static and dynamic objects, which is an advantage over motion segmentation approaches traditionally used in multibody SFM. Detailed experiments on the KITTI raw dataset show the superiority of the proposed method over both state-of-the-art motion segmentation and a baseline that heuristically uses detection bounding boxes for resolving occlusions. We also demonstrate how our continuous occlusion model may be applied to the task of 3D localization in road scenes.
-
Pinhole camera workshop for middle school students
-
Modern MAP algorithms for occupancy grid mapping
We propose to use modern graphical model inference techniques like Dual Decomposition and Belief Propagation for occupancy grid mapping.
 Using the inverse sensor model has been popular in occupancy grid mapping.
However, it is widely known that applying the inverse sensor model to mapping
requires certain assumptions that are not necessarily true. Even the works
that use forward sensor models have relied on methods like expectation
maximization or Gibbs sampling which have been succeeded by more effective
methods of maximum a posteriori (MAP) inference over graphical models. In this
paper, we propose the use of modern MAP inference methods along with the
forward sensor model. Our implementation and experimental results demonstrate
that these modern inference methods deliver more accurate maps more
efficiently than previously used methods.
Using the inverse sensor model has been popular in occupancy grid mapping.
However, it is widely known that applying the inverse sensor model to mapping
requires certain assumptions that are not necessarily true. Even the works
that use forward sensor models have relied on methods like expectation
maximization or Gibbs sampling which have been succeeded by more effective
methods of maximum a posteriori (MAP) inference over graphical models. In this
paper, we propose the use of modern MAP inference methods along with the
forward sensor model. Our implementation and experimental results demonstrate
that these modern inference methods deliver more accurate maps more
efficiently than previously used methods.
-
Voxel Planes
Paper, Bibtex, Presentation, Code
We propose using small planes inside voxels to model 3D surfaces and corresponding algorithms to reconstruct them fast and accurately.
 Our voxel planes approach first computes the PCA over the points inside a voxel, combining these PCA results across 2x2x2 voxel neighborhoods in a sliding window. Second, the smallest eigenvector and voxel centroid define a plane which is intersected with the voxel to reconstruct the surface patch (3-6 sided convex polygon) within that voxel. By nature of their construction these surface patches tessellate to produce a surface representation of the underlying points.
Our voxel planes approach first computes the PCA over the points inside a voxel, combining these PCA results across 2x2x2 voxel neighborhoods in a sliding window. Second, the smallest eigenvector and voxel centroid define a plane which is intersected with the voxel to reconstruct the surface patch (3-6 sided convex polygon) within that voxel. By nature of their construction these surface patches tessellate to produce a surface representation of the underlying points.
In experiments on public datasets the voxel planes method is 3 times faster than marching cubes, offers 300 times better compression than Greedy Projection, 10 fold lower error than marching cubes whilst allowing incremental map updates.
-
Kinfu based localization for Augmented Reality
Used Kinect Fusion based camera localization from PCL library to render augmented reality (using VTK) that enables user to add markers to describe arbitrary objects in 3D.
-
Head tracking using RGBD at Hackathon
We used OpenCV face detector, KLT feature tracker, VTK visualizer to cook up a head tracker at UB Hackathon 2013 within 24 hours.
-
Mutual Localization
Paper, Bibtex, Presentation, Code
We propose 3-point algorithm for two cameras to localize each other in 6-DOF. It is a generalization of Perspective-3-Point algorithm when the 3-Points are distributed and observed in two separate camera frames.
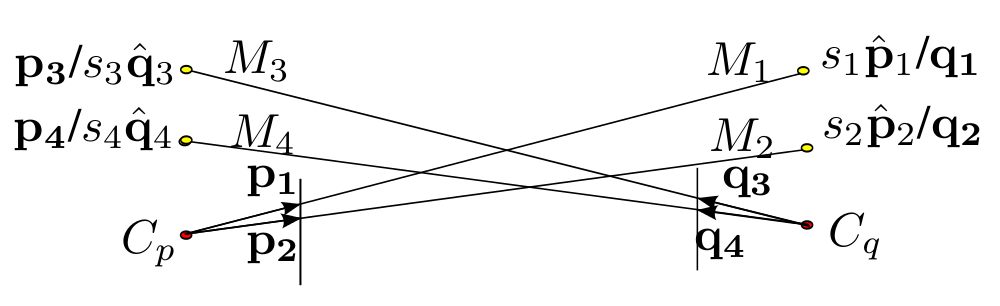 Concurrently estimating the 6-DOF pose of multiple cameras or
robots---cooperative localization---is a core problem in contemporary
robotics. Current works focus on a set of mutually observable world landmarks
and often require inbuilt egomotion estimates; situations in which both
assumptions are violated often arise, for example, robots with erroneous low
quality odometry and IMU exploring an unknown environment. In contrast to
these existing works in cooperative localization, we propose a cooperative
localization method, which we call \textit{mutual localization}, that uses
reciprocal observations of camera-fiducials to obviate the need for egomotion
estimates and mutually observable world landmarks. We formulate and solve an
algebraic formulation for the pose of the two camera mutual localization setup
under these assumptions. Our experiments demonstrate the capabilities of our
proposal egomotion-free cooperative localization method: for example, the
method achieves 2cm range and 0.7 degree accuracy at 2m sensing for 6-DOF
pose. To demonstrate the applicability of the proposed work, we deploy our
method on Turtlebots and we compare our results with ARToolKit and Bundler,
over which our method achieves a 10 fold improvement in translation
estimation accuracy.
Concurrently estimating the 6-DOF pose of multiple cameras or
robots---cooperative localization---is a core problem in contemporary
robotics. Current works focus on a set of mutually observable world landmarks
and often require inbuilt egomotion estimates; situations in which both
assumptions are violated often arise, for example, robots with erroneous low
quality odometry and IMU exploring an unknown environment. In contrast to
these existing works in cooperative localization, we propose a cooperative
localization method, which we call \textit{mutual localization}, that uses
reciprocal observations of camera-fiducials to obviate the need for egomotion
estimates and mutually observable world landmarks. We formulate and solve an
algebraic formulation for the pose of the two camera mutual localization setup
under these assumptions. Our experiments demonstrate the capabilities of our
proposal egomotion-free cooperative localization method: for example, the
method achieves 2cm range and 0.7 degree accuracy at 2m sensing for 6-DOF
pose. To demonstrate the applicability of the proposed work, we deploy our
method on Turtlebots and we compare our results with ARToolKit and Bundler,
over which our method achieves a 10 fold improvement in translation
estimation accuracy.
-
Multi-Resolution Occupied Voxel Lists
Added a few features like ROS support, support for color voxels to MROL library by Dr. Julian Ryde.
-
Work Experience
At DE Shaw, I have worked on various small automation projects like Web robots, web scrapers, feeds parsers etc. Most of the these applications were written in Perl and a few in Python. Apart from this I have also worked on a simple web application using J2EE. I used Hibernate, Struts 2 and Spring for the web application.
